How to Convert Scanned PDF Documents to Plain Text using Google Docs
If you have lots of invoices, business letters, contracts and other important paper documents that take up your office and work space, then the scanner is your best friend. You can scan any paper document to convert it to an electronic format and save it to your computer. The best and most popular format for archiving and storing documents is PDF.
But, if you need to search or edit these scanned PDFs, you will need OCR software to convert them to formats such as Word, Excel, PowerPoint. Sometimes, you may want to extract text from images or PDF documents and OCR software is the only way to extract or convert the image into a plain text file. There are many powerful paid OCR software solutions out there, but if you need OCR from time to time, for a random conversion, you may want to consider some free solutions that will be able to get the job done acceptably.
One simple, free way to convert your scanned PDFs to text is by using Google Docs.
Convert Your Scanned PDF’s To Plain Text With Google Docs
To make your scanned PDFs usable and searchable, follow these steps:
1. Visit Google Docs and login to your Google account.
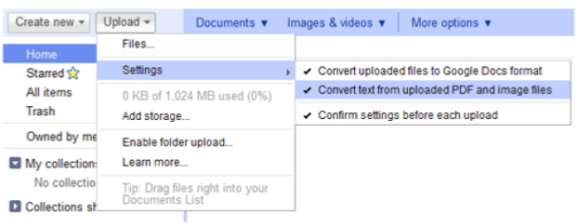
2. Click on the upload button, choose Settings and make sure to check the following two options
- Convert documents, presentations, spreadsheets and drawings to the corresponding Google Docs format
- Convert Text from uploaded PDF and image files.
3. Then simply upload your file and wait a few seconds to get the converted file. Look for the file in All Items; it will probably be at the top.
That’s all. If you want to see the result, here is a screenshot of the scanned PDF that I needed to convert to text format:

And here is the image of my converted file into plain text:

As you can see, the result of conversion is not perfect, but is certainly worth the money I paid for it. Actually, it’s free to be more precise
You can download your document from Google docs in a variety of formats such as Microsoft Word, text, rich text, open document (.odt) or even PDF.
Once downloaded in the desired, editable format, you can rework and format it, as well as copy and paste from it. Or, you can simply archive it as searchable PDF. Archiving important business documents, textbooks or interesting articles in electronic format helps you to unclutter your desk and shelves, but at the same time it also saves you time when you have to search for an exact contract or invoice.
Using Optical Character Recognition (OCR) In Google Docs To Extract Text From PDF And Scanned Documents
If you are using optical character recognition (OCR) in Google Docs to extract the text from your PDFs, it is good to know the following 5 things for achieving the best possible results:
- The maximum size of the uploaded image file is 2MB. Google Docs extracts text from the first 10 pages of the PDF document.
- Google Docs OCR engine support for non-Latin character sets is pretty limited, as it is still in its experimental phase.
- Files that include common fonts like Times New Roman and Arial will produce better results.
- The best conversion results are achieved with high-resolution files (at least 10px of height for each line of text is highly recommended).
- If your image PDF includes bulleted and numbered lists, tables, footnotes, text columns and similar formatting elements, they are probably going to be lost in the conversion process.
This is a guest article by David Lazar who blogs at PdfConverter.com. With a background in journalism, he enjoys writing and following all the latest trends related to technology and new media.